|
I am an enthusiastic Autonomous Driving Simulation Engineer working in ADX Stellantis simulation team, and participate in the Stellantis-BMW group R&D project AutoDrive1.0. I graduated from University of Michigan, Ann Arbor at May.2023, and got my master of science degree in Electrical and Computer Engineer. During my leisure time, I love snowboarding, videos games, cooking and watching movies. |

|
|



 ADAS Simulation Engineer (06/05/2023 - Present)
ADAS Simulation Engineer (06/05/2023 - Present)
 Advanced Engineer Intern (02/03/2023 - 05/01/2023)
Advanced Engineer Intern (02/03/2023 - 05/01/2023)
 Hardware Engineer Intern (06/01/2020 - 08/31/2020)
Hardware Engineer Intern (06/01/2020 - 08/31/2020)
My research interest lies in mobile robotics, machine learning, deep learning and computer vision. Most of my research is about robotics and deep learning for computer vision.
|
|
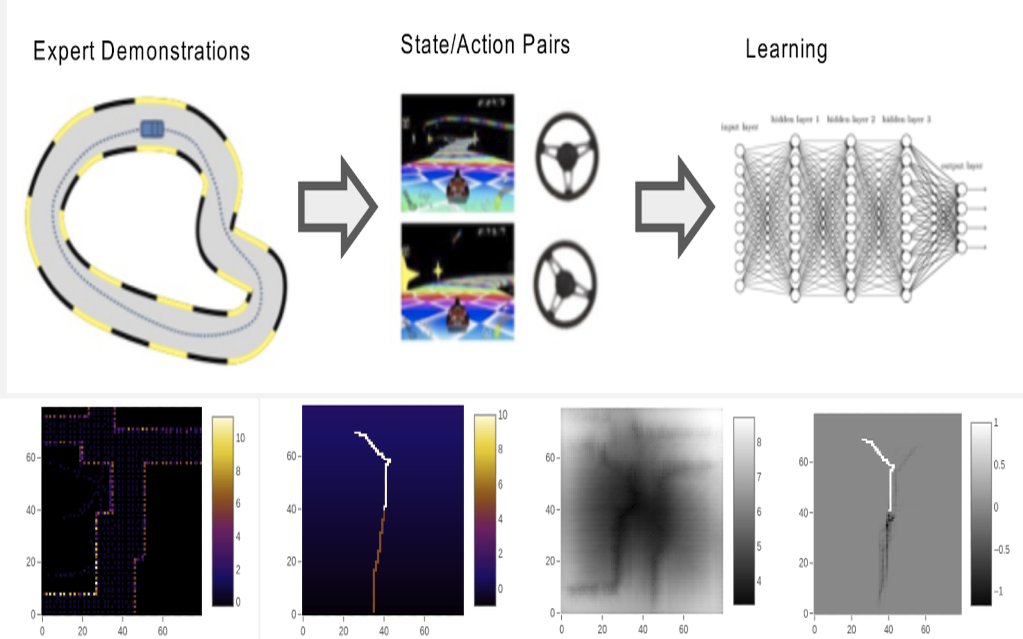
Fengkai Chen, Sangli Teng, Maani Ghaffari Information gathering is an critical and broadly studied task for mobile robotics operating in unknown environments. Incrementally-exploring information Gathering(IIG) algorithm takes a dense stochastic map of enviroment to collect information for exploration. While the information gathering process is time-consuming and unstable, we proposed a new information collect method which apply Inverse Reinforcement Learning(IRL). The IRL incorporates both exteroceptive and proprioceptive sensory data, and generate a reward map to replace original information of IIG exploration. The IRL will be trained on human demonstration in advance, and the inference process is sufficiently efficient. |
|
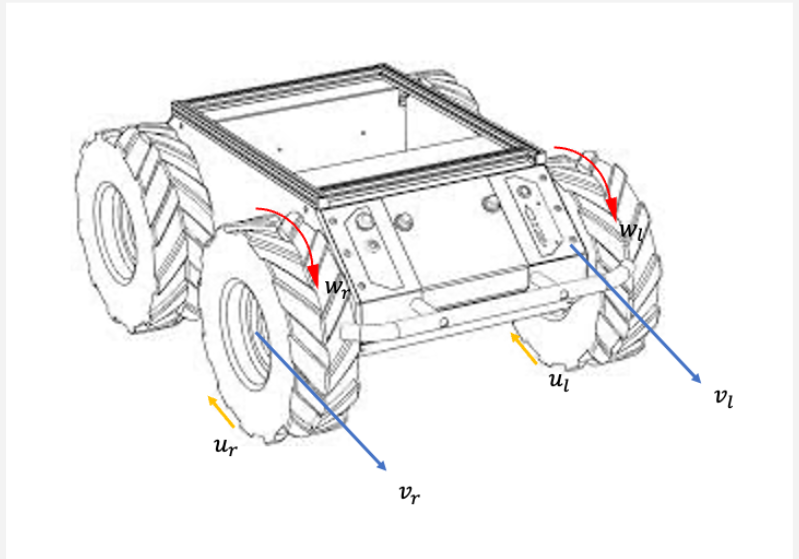
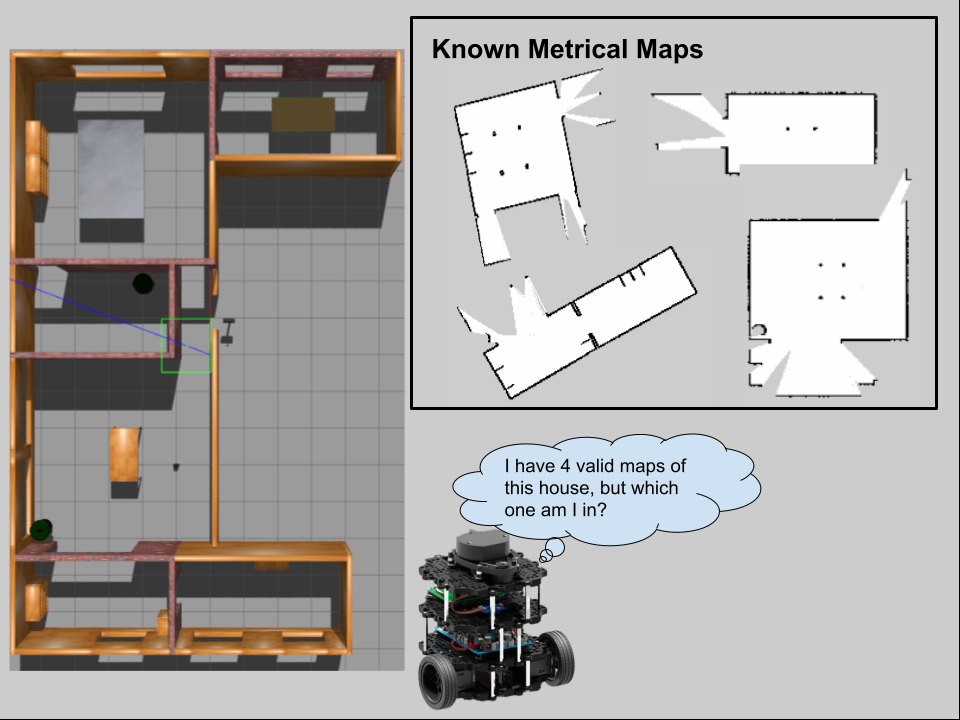
Fengkai Chen, Jake Olkin, Cameron Kisailus, Tianyang Shi, Sihang Wei PDF / video / code / colab In order to reliably deploy robots in large-scale environments, it is fundamental for robots to have accurate localization. Robot relocalization is the act of determining the position in a robot in a previously mapped environment. Relocalization in small-scale environments is usually done by maintaining a contiguous map of the entire environment, but this does not scale. Methods to combat this scaling problem have proposed splitting large, global maps into smaller metrical maps. However, this adds another dimension to the relocalization problem, since the algorithm must additionally determine which map is it located on. Probabilistic localization algorithms are governed by the total law of probability, so it is impossible to indicate low, or even zero, belief a robot is anywhere on a given map (i.e. a particle filter will always maintain some belief of the robot location) |
|
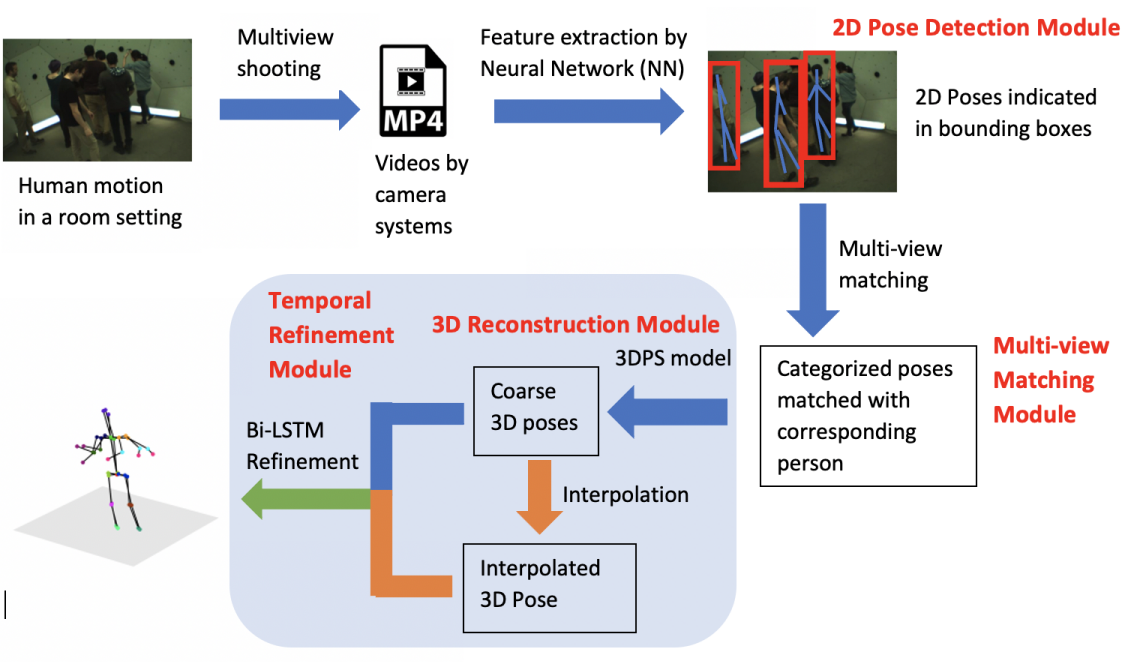
Fengkai Chen, Feiyu Zhang, Han Zheng, Zhuoting Han Recent studies have witnessed the successes in applying deep learning approach 3D pose estimation. However, most of the 3D pose estimation models are either monocular or operating on single frames, which may not fully exploit the multi-view videos. To fill this gap, we propose a Bi-LSTM based 3D pose estimation model in multi-view videos, which can refine a 3D pose over an entire sequence from multi-view cameras. Our method outperforms the single frames-based model on dataset like Campus – where we show quantitative improvements – and successfully reconstruct 3D pose videos. By temporal refinement on single frames 3D poses, we effectively encode multi-view pose within a unified 3D framework. Furthermore, we propose a method to use temporal refinement module to improve the existing single frames-based 3D pose estimator. We show that our model can be extensive, which allows other deep learning-based models to retrain on previous estimated 3D pose following our paradigm. |
|
|